
Text- und Data-Mining
Automatisierte Auswertung von Forschungsdaten

Die automatisierte, auf Algorithmen gestützte Auswertung großer Datenmengen spielt in Wissenschaft, Industrie und Gesellschaft eine immer größere Rolle. Für die Anwenderinnen und Anwender solcher Analyseverfahren geht damit die Frage einher, unter welchen Voraussetzungen Text- und Data-Mining erlaubt ist. Speziell für die Wissenschaft existiert mit § 60d UrhG dafür seit 2018 eine gesetzliche Regelung.

Unter welchen Voraussetzungen darf Text- und Data-Mining durchgeführt werden?
Bevor Daten automatisiert analysiert werden bzw. Datensammlungen zu diesem Zweck angelegt werden, sollte geklärt werden, ob eine solche Nutzung zulässig ist.
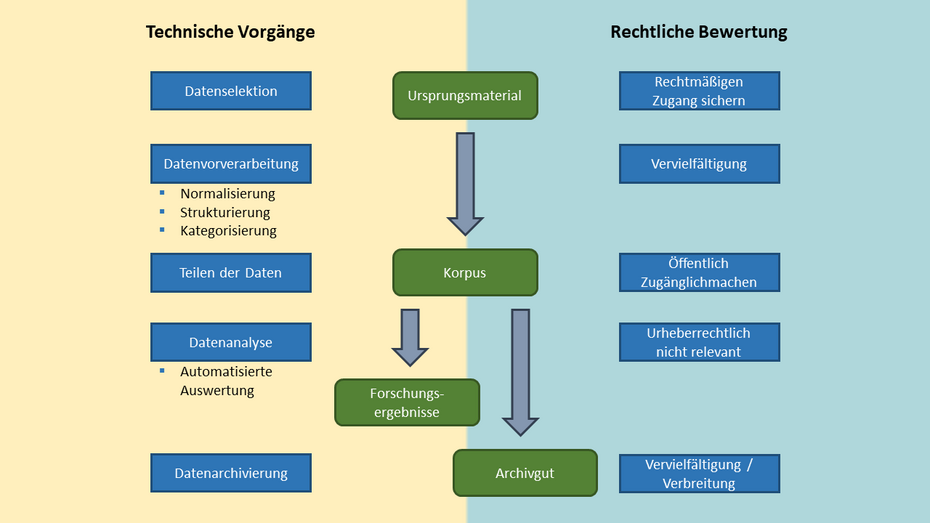
- Zunächst muss geprüft werden, ob Rohdaten bzw. Ursprungsmaterialien überhaupt urheberrechtlich geschützt sind. Andernfalls ist Text- und Data-Mining urheberrechtlich erlaubt. Beispielsweise genießen quantitative Daten z.B. aus den Naturwissenschaften oft keinen urheberrechtlichen Schutz. Anders verhält es sich mit qualitativen Daten (z. B. Interviews in den Sozialwissenschaften). Allerdings können nicht nur einzelne Daten, sondern auch die Datenbanken, aus denen diese entnommen werden sollen, urheberrechtlichen Schutz genießen. Sofern es sich um personenbezogene Daten handelt, sind zudem datenschutzrechtliche Einschränkungen zu beachten.
- § 60d UrhG gewährt kein Recht auf Zugang zu den zu analysierenden Daten, sondern setzt diesen vielmehr voraus. Das bedeutet, dass die Ursprungsmaterialien ggf. von den Rechteinhabern lizenziert werden müssen. Allerdings stehen in manchen Fällen kostengünstigere Alternativen offen: so dürfen z. B. in der eigenen Einrichtung vorhandene analoge Bestände zum Zwecke des Text- und Data-Mining digitalisiert werden. Dies gilt sogar für per Fernleihe beschaffte Werke.
- Die Vorschrift schützt nur nicht-kommerzielle wissenschaftliche Forschung. Entscheidend ist, ob das Forschungsvorhaben auf Gewinnerzielung ausgerichtet ist. Daher kann sich z. B. bezahlte Auftragsforschung an Universitäten nicht auf § 60d UrhG berufen. Soweit sich eine Förderung durch Drittmittel aber auf die Deckung der Kosten beschränkt, ist dies unproblematisch.
Was ist nach § 60d UrhG erlaubt – was ist verboten?
Nicht zuletzt sollte von Beginn an Klarheit darüber bestehen, wie urheberrechtlich geschützte Materialien im Rahmen des Text- und Data-Mining genutzt werden dürfen:
- § 60d UrhG erlaubt es, das Ursprungsmaterial zu kopieren und zu speichern (vervielfältigen), um daraus durch Normalisierung, Strukturierung, Kategorisierung oder andere Aufbereitungsmethoden ein Korpus zu erzeugen. Zwar gewährt die Norm keinen Anspruch auf bestimmte, z.B. maschinenlesbare Dateiformate, sehr wohl aber dürfen die Daten im Rahmen des Text- und Data-Mining in ein anderes Format konvertiert werden.
- Innerhalb einer Forschungsgruppe darf das erstellte Korpus elektronisch geteilt werden (öffentlich zugänglich machen). Voraussetzung ist, dass es sich um einen abgrenzbaren Personenkreis handelt. Nicht zwingend ist hingegen, dass die involvierten Personen alle an der gleichen Einrichtung forschen. Auch im Rahmen von Begutachtungs- bzw. Review-Prozessen darf das Korpus verfügbar gemacht werden. Nicht zulässig wäre es demgegenüber, die Ursprungsmaterialien bzw. das Korpus auf der eigenen Webseite zu veröffentlichen.
- Die automatisierte Auswertung des Korpus ist ebenfalls erlaubt, da sie keine urheberrechtlich relevante Nutzung darstellt.
- Nach Abschluss des Forschungsvorhabens müssen die Forschenden Vervielfältigungen und Korpus löschen; eine dauerhafte Speicherung ist nicht erlaubt. Um die Referenzier- und spätere Überprüfbarkeit der Ergebnisse trotzdem zu gewährleisten, dürfen das Korpus und Vervielfältigungen des Ursprungsmaterials an eine Bibliothek, Archiv, Museum oder andere öffentlich zugängliche Bildungseinrichtung zur Archivierung übermittelt werden.
Was wird sich durch die neue DSM-Richtlinie ändern?
Bis spätestens 2021 muss der deutsche Gesetzgeber die rechtlichen Regeln zum Text- und Data-Mining anpassen. Dazu liegt bereits ein erster Regierungsentwurf vor. Hintergrund ist die sog. DSM-Richtlinie (= RL (EU) 2019/790), die insbesondere im Hinblick auf „Upload-Filter“ in Öffentlichkeit und Medien kontrovers diskutiert wurde. Die Richtlinie weitet den rechtlichen Freiraum für Text- und Data-Mining aus und bringt insbesondere drei wesentliche Verbesserungen mit sich:
- Zukünftig ist Text- und Data-Mining nicht nur für wissenschaftliche Forschung, sondern für jedermann (z.B. auch Unternehmen, die Presse und Privatleute) erlaubt (Art. 4 DSM-Richtlinie). Forschungseinrichtungen und Einrichtungen des Kulturerbes sind aber privilegiert, da die Rechteinhaber ihnen Text- und Data-Mining nicht durch einen Vorbehalt verbieten können (Art. 3 DSM-Richtlinie).
- Die Regeln zur Speicherung und Archivierung werden großzügiger. Insbesondere wird für die Forschenden auch eine langfristige Speicherung zulässig.
- Es wird für die Rechteinhaber schwieriger Text- und Data-Mining durch technische Schutzmaßnahmen zu verhindern.